Java Applet on Stochastic FSM Encoding
APPLET MANUAL
Stochastic FSM Encoder is a set of tools, which perform FSM state assignment based on the results of its stochastic analysis. The software uses FSM description in KISS2 format as input data. Functionality, which is provided by the application, is divided into three tabs with common information console. Each tab performs certain class of operations on the FSM.
1. FSM Manager Tab
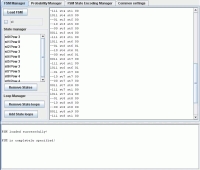
“FSM Manager” is the first tab, which loads input data, performs integrity analysis and allows to make appropriate adjustments. The tab view is shown on Figure 1. To the right is a special text area, where FSM description in KISS2 format should be place. Press “Load FSM” button to read the specified description. In case KISS2 description contains errors, application reports type and line number for each encountered error in information console. Otherwise, “FSM loaded successfully!” message is printed. The loaded FSM is then checked to determined whether it is completely specified or not. The application reports a list of states with incomplete transition cover (if any) in information console. Otherwise, “FSM is completely specified!” message is printed.
This tab also provides a simple state renaming capability. The mechanism is activated by setting a check-box before the FSM description is loaded. The new state prefix should be written into the text field (“st” by default). After FSM description is loaded, the states are renamed according to the specified convention. It is still possible to switch over to the original names by disabling the check-box.
“State Manager” block provides a list of states for the loaded FSM description. Any state on that list can be removed by selecting the corresponding state and pressing “Remove States” button. The application removes chosen states along with all transitions leading to or from that state in the loaded FSM description.
Figure 1: “FSM Manager” tab view
“Loop Manager” block manipulates the set of loop transitions for the loaded FSM descriptions. This module contains two buttons: “Remove State loops” and “Add State Loops”. “Remove State Loops” button checks every state for self loop transitions and removes them from loaded FSM description. “Add State Loops” button checks every state for unspecified transitions and inserts self loops into loaded FSM description to form a full cover. Each procedure is acknowledged with “States loops are removed!” or “States loops are added!” message respectively in information console.
2. Probability Manager Tab
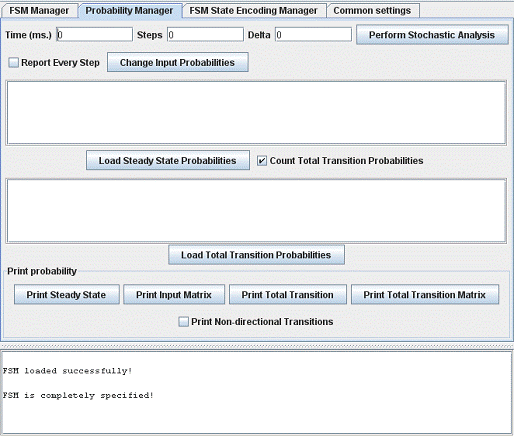
“Probability Manager” is the second tab, which allows to perform stochastic analysis of the loaded FSM and print the results. Probabilistic model can be imported from external source as well. The tab view is shown on Figure 2.
Figure 2: “Probability Manager” tab view
As stochastic analysis is a rather time consuming task, the calculation process can be subjected to some limitations. In “Time (ms)” text field the duration of stochastic analysis in milliseconds can be defined. Similarly, the content of “Steps” text field defines the number of steps to be performed during computation. “Delta” text field sets the target accuracy. To start the stochastic analysis press “Perform Stochastic Analysis” button. When any of the specified limitations expire, the calculation is stopped. In order to receive information on every step of the analysis, set the “Report Every Step” check-box. Otherwise, only summary is printed in the information console.
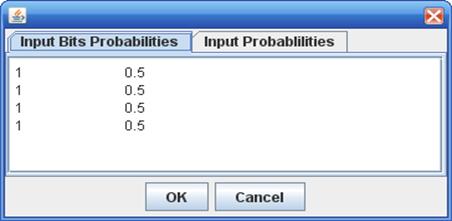
Clicking “Change Input Probabilities” button opens a new window (Figure 3), where input probabilities for the loaded FSM description can be defined (equiprobable by default).
Figure 3: “Input Bits Probabilities” tab on “Change Input Probabilities” frame
After editing the data, changes are confirmed by pressing “OK” button. The control is automatically transferred to the next tab (Figure 4).
Figure 4: “Input Probabilities” tab on “Change Input Probabilities” frame
On “Input Probabilities” tab, probability for each input combination is listed. This data is calculated based on the input probabilities provided on previous tab. However, one can manually edit the final probability distribution regardless of the first tab content. In order to simplify entry process, the support for “don't care” sign has been added. Therefore, combinations like “---- 0.0625” or “00-1 0.125” are considered “understandable”. After editing the data, changes are confirmed by pressing “OK” button. To cancel changes either press “Cancel” button or close the window.
The stochastic analysis provides steady state probability distribution for the loaded FSM description, which is then used to calculate the final transition probabilities. However, both stochastic estimations can be specified manually as well. Probabilistic model can be defined using any numbers (positive, negative, less than “1”, more than “1”), it does not matter. That is because state encoding algorithm uses these probabilities like weight coefficient.
In order to allow manual entry of steady state probability distribution and total transition probabilities, two text area fields are provided. The upper field is used for steady state probability entry. It takes data in the following format “st1 0.33”, where “st1” is the state name and “0.33” is the corresponding steady state probability. The new data is applied after pressing “Load Steady State Probabilities” button. If the “Count Total Transition Probabilities” check-box is also set, then total transition probabilities for the newly entered data will be calculated automatically as well.
The lower text area field is used for total transition probability entry. It takes data in the following format “st1 st2 0.125”, where “st1” is the name of the current state, “st2” is the name of the next state and “0.125” is the corresponding total state transition probability. The new data is applied after pressing “Load Total Transition Probabilities” button.
Probability distribution can be defined either for all states (transitions) or only for a certain number of them. If probability distributions have already been defined (stochastic analysis has been performed), the newly loaded data affects only specified states (transition), while others retain their values. Otherwise, unspecified states (transitions) will be left undefined, which would most likely result in erroneous behavior.
The resultant stochastic data can be viewed in information console. To print steady state probability distribution click “Print Steady State” button. The data is presented in the following format “st1 0.33”, where “st1” is the state name and “0.33” is the corresponding steady state probability. “Print Input Matrix” button shows the transition probability distribution as a matrix, where each row or column corresponds to FSM state. Each element of this matrix represents a transition probability from a “row” state to a “column” state. Zero probability means that there is no transition between these two states.
To print total transition probabilities click “Print Total Transition” button. The data is presented in the following format “st1 st2 0.125”, where “st1” is the name of the current state, “st2” is the name of the next state and “0.125” is the corresponding total state transition probability. “Print Total Transition Matrix” button prints the same probabilities in matrix view, where each row or column corresponds to FSM state. Each element of this matrix represents a total transition probability from a “row” state to a “column” state. Zero probability means that there is no transition between those states.
There is also “Print Non-directional Transitions” check box, which affects “Print Total Transition” and “Print Total Transition Matrix” buttons only. When this check-box is set, these buttons print probabilities for nondirectional transitions. It means that, for example, transitions like “st1 st2 0.125” and “st2 st1 0.125” are printed as one transition “st1 st2 0.25” (or possibly “st2 st1 0.25”). Therefore, matrix representation becomes is symmetric.
3. FSM State Encoding Manager Tab
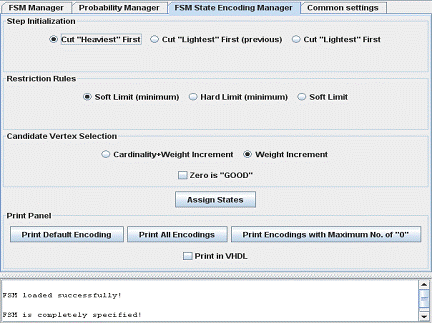
“FSM State Encoding Manager” is the third tab, which performs FSM state assignment based on the results of its stochastic analysis. The main idea of this algorithm is to minimize the Hamming distance (number of bits by which two codes differ) between adjacent states with higher transition probability. The tab view is shown on Figure 5.
Figure 5: “FSM State Encoding Manager” tab view
The first block (on the top on the tab) is called “Step Initialization”. This block defines the initial distribution of states prior to step execution. Currently the following initialization strategies are implemented: “Cut “Heaviest” First”, “Cut "Lightest" First (previous)” and “Cut "Lightest" First”. If for some reasons it becomes impossible to perform state assignment after initial allocation of states, the application throws exception.
State assignment should be performed in accordance with a set of restriction rules, which ensure the correctness of the obtained encoding. The “Restriction Rules” block (in the middle of the tab) allows to choose between th rule sets, which are called “Soft Limit (minimum)”, “Hard Limit (minimum)” and “Hard Limit”.
“Candidate Vertex Selection” block (at the bottom of the tab) defines the strategy, which is used to find the best candidate among undistributed states. Current implementation supports two criteria: “Cardinality+Weight Increment” and “Weight Increment”. Setting the check-box “Zero is GOOD” tells the algorithm, that a zero value of the increment should be considered as an improvement.
After configuration of the algorithm is selected, press “Assign States” button to start the encoding algorithm. The progress of the algorithm is shown in information console. After state assignment is obtained, the application checks whether the resultant encoding is unique or not. The result of this check is printed in information console. If state assignment has been performed successfully, the defect is calculated in order to provide an estimation of the quality for the obtained encoding. It is also listed in information console.
The “Print Panel” block allows to output results of encoding process in the information console. “Print Default Encoding” button prints the resultant state assignment as generated by the algorithm. “Print All Encodings” button prints all possible variations of the resultant state encoding, which can be obtained by swapping values of certain bit positions. “Print Encodings with Maximum No. of “0”” button prints only those variations, where number of zeros in the state codes is maximum. Setting the “Print in VHDL” check-box allows to print the encoding as VHDL code.
4. Common Settings Tab
This is the last tab, which defines common settings for the whole application. “Print accuracy” drop-down menu allows to specify the number of digits after decimal point. This setting affects only to the “print” accuracy, internal calculations would still proceed with maximum precision. “Sort FSM States by” drop-down menu allows to select how to sort FSM states before placing the list in the information console. Using this tool we can sort FSM states by name or by weight. Confirm changes by pressing “OK” button.
Figure 6: “Common Settings” tab view
Last update: November 2009